
Metadata in Content Management – Part 2
Originally posted by Troy Allen on CMSWire on January 10, 2011.
Abstract: The following article has been split between two parts. Part two continues to provide an overview of Metadata in Content Management.
Dublin Core is a Common Model for Content Management
For traditional corporate Content Management, many organizations adopt a version of the Dublin Core model which is one of the most well known and established standards. The essence of the Dublin Core states that content will be described by metadata that:
- Address Functional Requirements – The main repository or any application that connects to the repository for managed content will be performing specific tasks. Metadata should be constructed to address these functions. As an example, content may be called from a Web App which may have certain search and security requirements.
- Develop A Domain Model – A domain model is a description of the things the metadata model will describe and the relationship between those things such as a person or author is described by a name, location and email address.
- Define Metadata Terms – Metadata terms are the properties that describe the things in the model. For example, a press release would have a title, release date, author and topic. An author can have a name, location or address and email address.
- When designing a model using this approach, there are many dependencies that need to be addressed and it can be difficult to keep them organized. Before an organization begins to build their model, the following guidelines can help to keep this manageable and usable:
- Minimize the number of metadata fields for a type of content – When users are presented with a large number of fields that they have to enter data into, they will find ways to avoid filling them out. Users are usually in a hurry and just want to get their files into a repository. Make their tasks more streamlined by only asking them to fill out a few important fields.
- Avoid “Nice to have” fields – Organizations can easily fall into the trap of having too much data describing their content that isn’t need or will rarely be used. For example, I had a customer once who wanted a metadata field for capturing the font type used within the managed document. Since the customer was not a “Publishing House”, there was no need to store this data and it would have just been an extra field for the end-user to fill out.
- Create a Global set of fields – Every department within an organization will have specific metadata requirements for their own business needs, but there should be a well defined set of cross-organization fields that any user can search on to find content.
- Use Pre-defined lists when possible – Free form metadata fields are notorious for user error and poor searching.
The following is an example of building a Metadata model, loosely derived from the Dublin Core methods and keeping the above guidelines in mind:
Metadata Model for Managed Email Repository
Requirements: Allow users to search for emails based on standard email attributes in addition to priority classifications. Require users to supply pertinent metadata values during check-in procedures to ensure search ability. 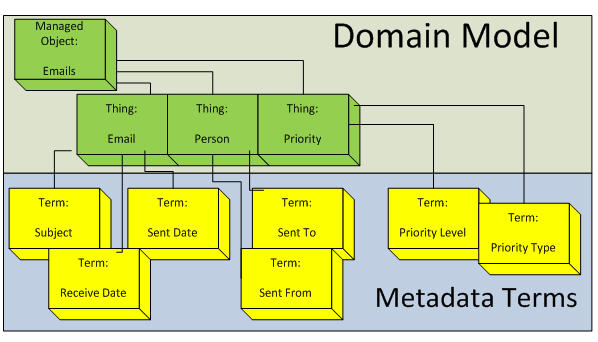
Domain Model: Managed Object – Emails
- Content Type – Email
- Responsible Parties
- Sender
- Recipient
- Priority
- Level
- Type
Metadata Terms and Fields:
- Content Type – Emails (Auto Selected)
- Receive Date – (Date Field)
- Sent Date – (Date Field)
- Subject – (free form field)
- Sender – (free form field)
- Recipient – (free form field)
- Priority Type – (predefined list)
- Value 1 – General Correspondence
- Value 2 – Legal Correspondence
- Value 3 – Sales Correspondence
- Value 4 – Human Resource Correspondence
- Priority Level – (Predefined list)
- Value 1 – No action required
- Value 2 – Immediate action required
- Value 3 – Management action required
Final Thoughts
For an organization which will manage many different types of content within the repository, each content type might have its own structure. Mapping out the requirements, domain and terms will help to keep information organized, allow administrators to see duplicate fields, and asses what is absolutely needed and what is extra data that is being stored. Modeling like this can take anywhere from a week to several months depending on the size of the application(s) involved, type of data being managed and size of the organization.